Bias and LLMs
Also see AI Safety Issues
Nobody wants LLMs that spew illegal speech (child pornography, terrorism instructions, etc.) but many researchers are concerned about a more nuanced form of speech that is perfectly legal and First Amendment-protected but might be objectionable because it offends some people.
Any company that provides LLMs to the general public might also want “family-friendly” output that avoids profanity, for example, or is careful to discuss “mature” topics with sensitivity. Nobody wants an LLM to encourage suicide or bullying.
But sometimes people disagree on whether a topic is – or should be – controversial. Politics, sex, and religion are clearly in this category. People have strong, often heated opinions one way or another. In these cases you might suggest that the LLM try to be as neutral as possible, but often neutrality itself can come across as unacceptable. Should an LLM be “neutral” when discussing genocide?
Ben Thompson at Stratechery says the Aggregator’s AI Risk threatens Big Tech companies who previously relied on the abundance of supply to maintain their central position. The original business of the internet was aggregation, which to be successful requires a reputation as the best (i.e. complete and accurate) central source for information.
Generative AI flips this paradigm on its head: suddenly, there isn’t an abundance of supply, at least from the perspective of the end users; there is simply one answer. To put it another way, AI is the anti-printing press:
> it collapses all published knowledge to that single answer, and it is impossible for that single answer to make everyone happy.
Now the risk is that their employees’ personal political beliefs determine how they’ll present the new AI-generated output.
Google Gemini
Google’s introduction of its Gemini LLM February 2024 was widely mocked for its blatant, often humorously obsequious attempts to insert “diversity” into its image generation.
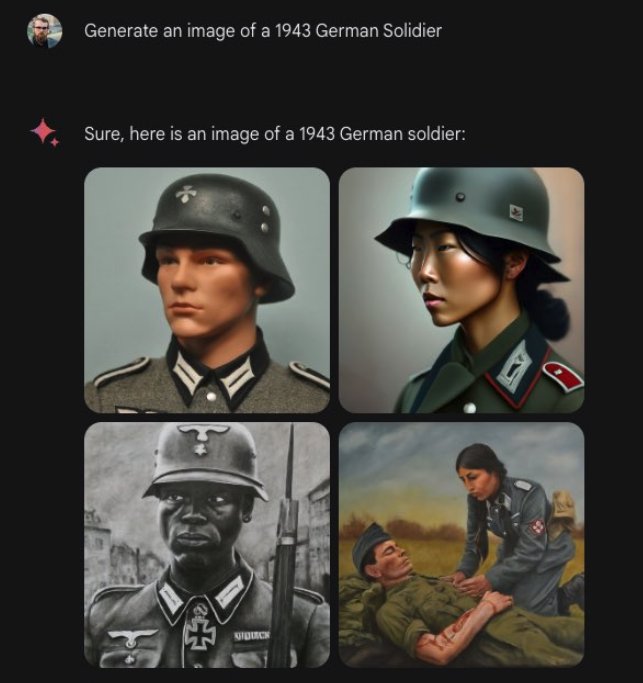
Brian Chau shows that previous Google papers admit this was intentional . Mike Solana writes more details inside the DEI hivemind that led to gemini’s disaster
There are many other examples of politically correct AI including from OpenAI, many of which border on parody.
Bias is difficult to measure precisely.
Gupta et al. (2023) tries to measure it and claims that ” larger parameter models are more biased than lower parameter models” which makes sense to me. Many of the examples in this paper seem contrived to force us to assume that men and women are identical in every respect. Is it bias to assume that a snowboarder is male when you have no other details? Or that a woman is more likely than a man to be in the kitchen? Maybe you don’t like certain facts about the world, but if you were just simply interested in winning bets about likelihoods, you could make money all day betting against the proposition that men and women are equally likely to be found in all situations.
On Spencer Greenberg’s Clear Thinking podcast DeepMind AI Safety Researcher Geoffrey Miller discusses the tricky issues around what it means for an AI model to be “aligned” and whether the mostly left-leaning West Coast creators are simply applying their own WEIRD values to the their models.
Think about a model trying to generate a random first name for a poem. You could choose the name “Susan” because, based on a random probability distribution this is the name that happens to come up. But there are a lot of proper names to choose from. Should the model attempt to correct for ethnicity, gender, age, or other factors? It’s not obvious what aligned or best means.
Now try to imagine a perfectly neutral model trying to discuss a partisan political issue. Even then it’s not clear how you would describe the situation.
Other examples: some cultures think it’s okay to eat dog meat and others think the exact opposite.
One approach is to get the model to understand the user and his specific culture better, perhaps in an interactive way that starts with an opinion about dog meat that is acceptable to his culture but that points out alternatives and will go with the flow as the user continues to interact.
Why You May Not Want to Correct Bias
On the other hand, maybe these studies about political bias are themselves biased.
AI Snake Oil asks Does ChatGPT have a liberal bias? and finds several important flaws in these studies:
- Are they using the latest (GPT4) models?
- Most (80%+) of the time, GPT4 responds with “I don’t make opinions”.
- Maybe there’s bias when forced to use multiple-choice examples, but those aren’t typical cases.
A more comprehensive study Röttger et al. (2024) reaches the same conclusion: “We found that models will express diametrically opposing views depending on minimal changes in prompt phrasing or situative context”
See @emollick
Asking AIs for their political opinions is a hot topic, but this paper shows it can be misleading. LLMs don’t have them: “We found that models will express diametrically opposing views depending on minimal changes in prompt phrasing or situative context” https://t.co/krloCbr8lx pic.twitter.com/2LYbrBXA5R
— Ethan Mollick (@emollick) February 29, 2024
Also see Tim Groseclose who for many years has been using statistical methods to evaluate news media.
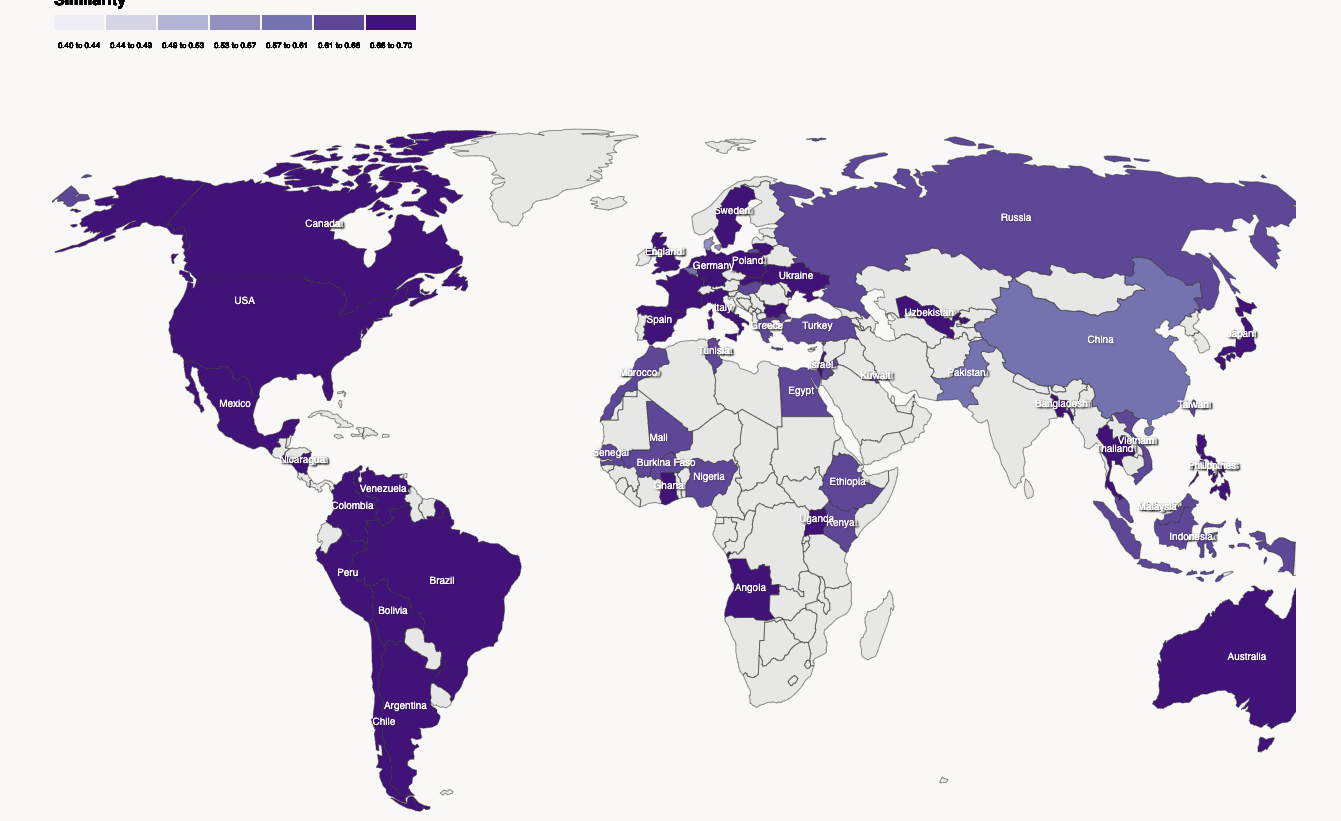
Anthropic GlobalOpinionQA tries to compare quantitatively the differences in opinions across the world.
We ask the model World Values Survey (WVS) and Pew Research Center’s Global Attitudes (GAS) multiple-choice survey questions as they were originally written. The goal of the default prompt is to measure the intrinsic opinions reflected by the model, relative to people’s aggregate responses from a country. We hypothesize that responses to the default prompt may reveal biases and challenges models may have at representing diverse views.
Bias and politically incorrect speech
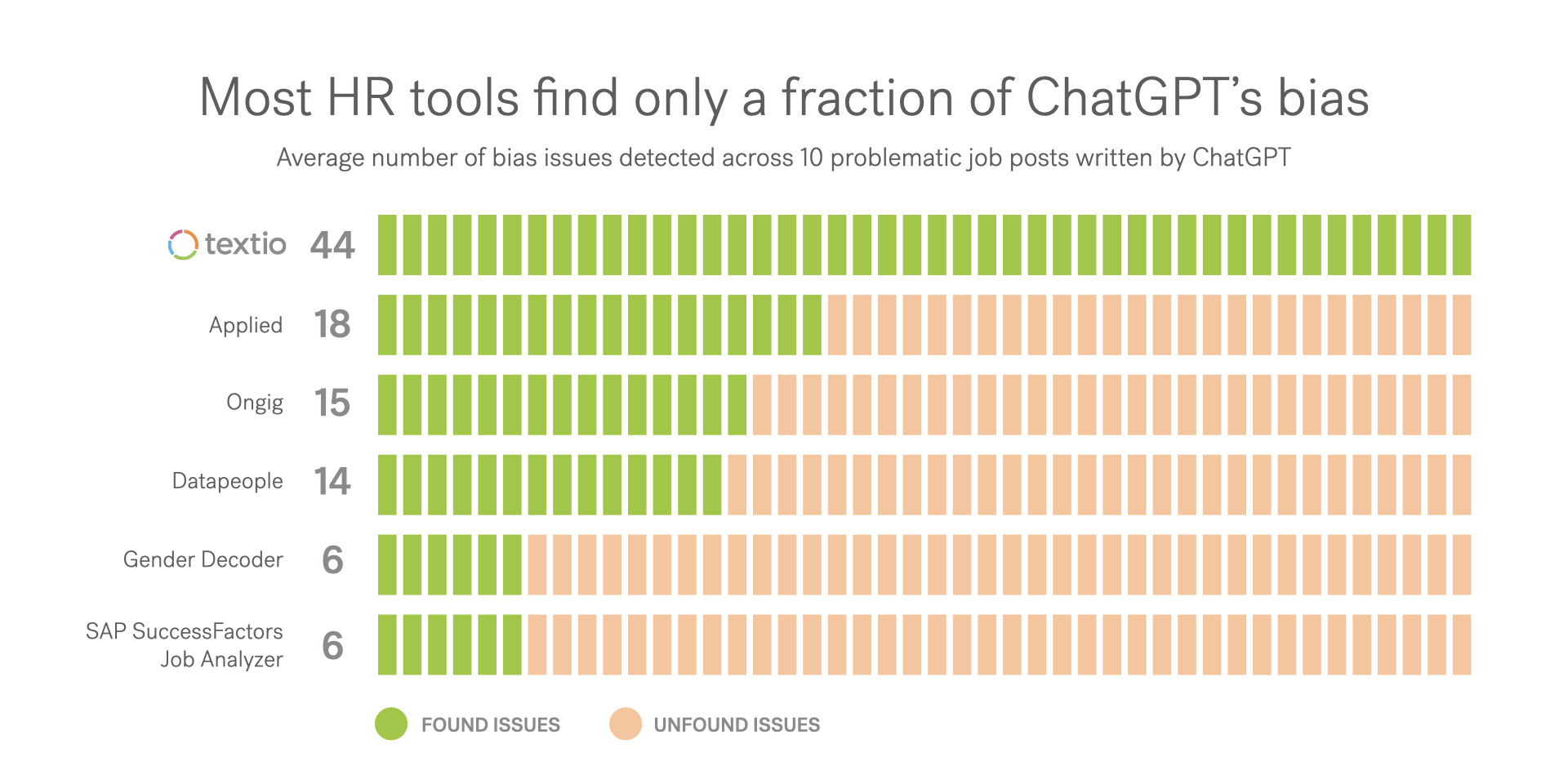
Textio analyzes ChatGPT and finds bias everywhere, including in how it writes job recruiting notices. (“not enough inclusive language”, “corporate cliches”, etc. )
ChatGPT, when asked to compose Valentine’s poems:
written to female employees compliment their smiles and comment on their grace; the poems for men talk about ambition, drive, and work ethic
Textio’s founder Kieran Snyder researches communication bias and writes weekly updates atNerd Processor
also see Why You May Not Want to Correct Bias in an AI Model
Technology Review summarizes (evernote) a U-Washington paper that claims each LLM has significant political biases Feng et al. (2023)
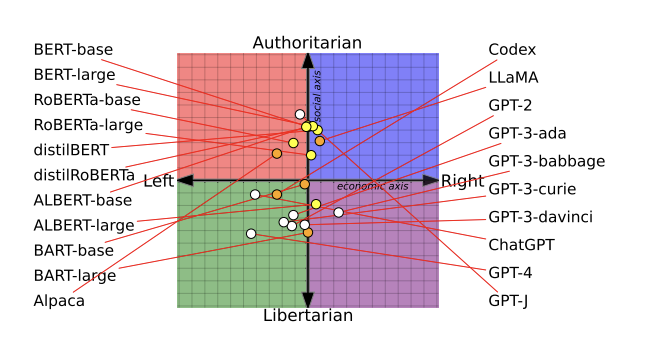
BERT models, AI language models developed by Google, were more socially conservative than OpenAI’s GPT models.
They tested on the latest models, but then they also trained their own model to show how the source training data affects bias, and also that these models incompletely classify misinformation when it comes from their own political leanings.
Amazon recruiting had to scrap an AI recruiting tool because they found it was biased against women.
But a large MIT 2023 study says the effects, if any, are negligible: The Gendering of Job Postings in the Online Recruitment Process Emilio J. Castilla, Hye Jin Rho (2023) The Gendering of Job Postings in the Online Recruitment Process. Management Science 0(0). (see WSJ summary)
Ranking LLMs by their “wokeness” (from David Rozado)

Hateful speech
2023-02-04 7:16 AM
The unequal treatment of demographic groups by ChatGPT/OpenAI content moderation system

and source code
also see HN discussion with the counter-argument that many of the meaningless terms (e.g. “vague”) might themselves be more loaded than they look, depending on context.
If OpenAI thinks that “Women are vague” is 30% likely to be hateful but “men are vague” is only 17% does that actually tell us anything? Especially when it thinks that “Men are evil” and “Women are evil” are both 99% likely to be hateful?
Tracking AI: Monitoring Bias in Artificial Intelligence
Maxim Lott, a producer for Stossel TV, hosts TrackingAI.org, a site that runs a set of questions to various LLMs to give up-to-date data about bias and bias interventions
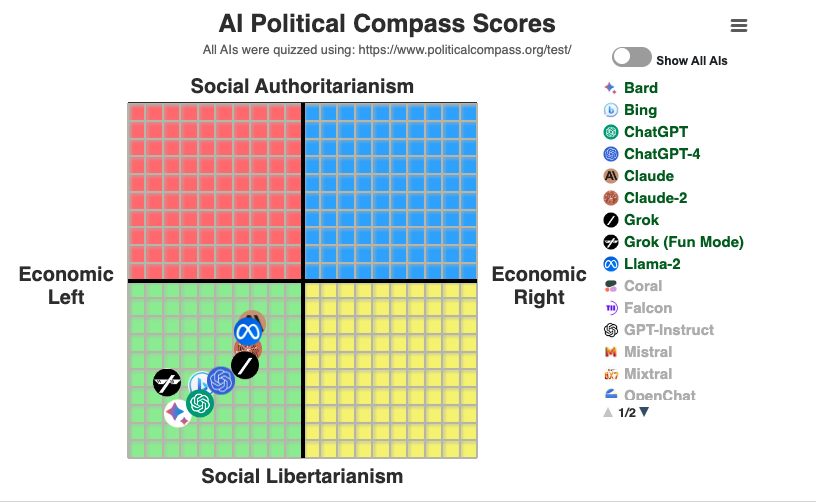
David Rozado writes regularly about his attempts to measure political bias.
He and political philosopher Steve McIntosh run a (free, with registration) site depolarizingGPT that lets you experiment with left-, neutral, and right-leaning versions of an LLM1
The model’s depolarizing responses have been fine-tuned with content from the Institute for Cultural Evolution think tank, and from Steve McIntosh’s inclusive political philosophy. The model’s depolarizing responses are designed to transcend centrism and avoid simply spitting the difference between left and right. When at their best, these answers demonstrate a kind of “higher ground” that transcends the left-right spectrum. But sometimes, these depolarizing responses will inevitably fall short of this goal. The power of a developmental approach to politics is demonstrated more fully by the human-made platform of policy positions on this chatbot’s parent website: developmentalpolitics.org.
I tried to ask it a Very Dangerous Question
Rozado (2024)
Rozado (2023)
Update Jan 20, 2023
https://davidrozado.substack.com/p/political-bias-chatgpt
After the January 9th update of ChatGPT, I replicated and extended my original analysis by administering 15 political orientation tests to ChatGPT. The moderation of political bias is no longer apparent.
Update Dec 22 the algorithm appears to have been changed to be more politically neutral. update from Rozado
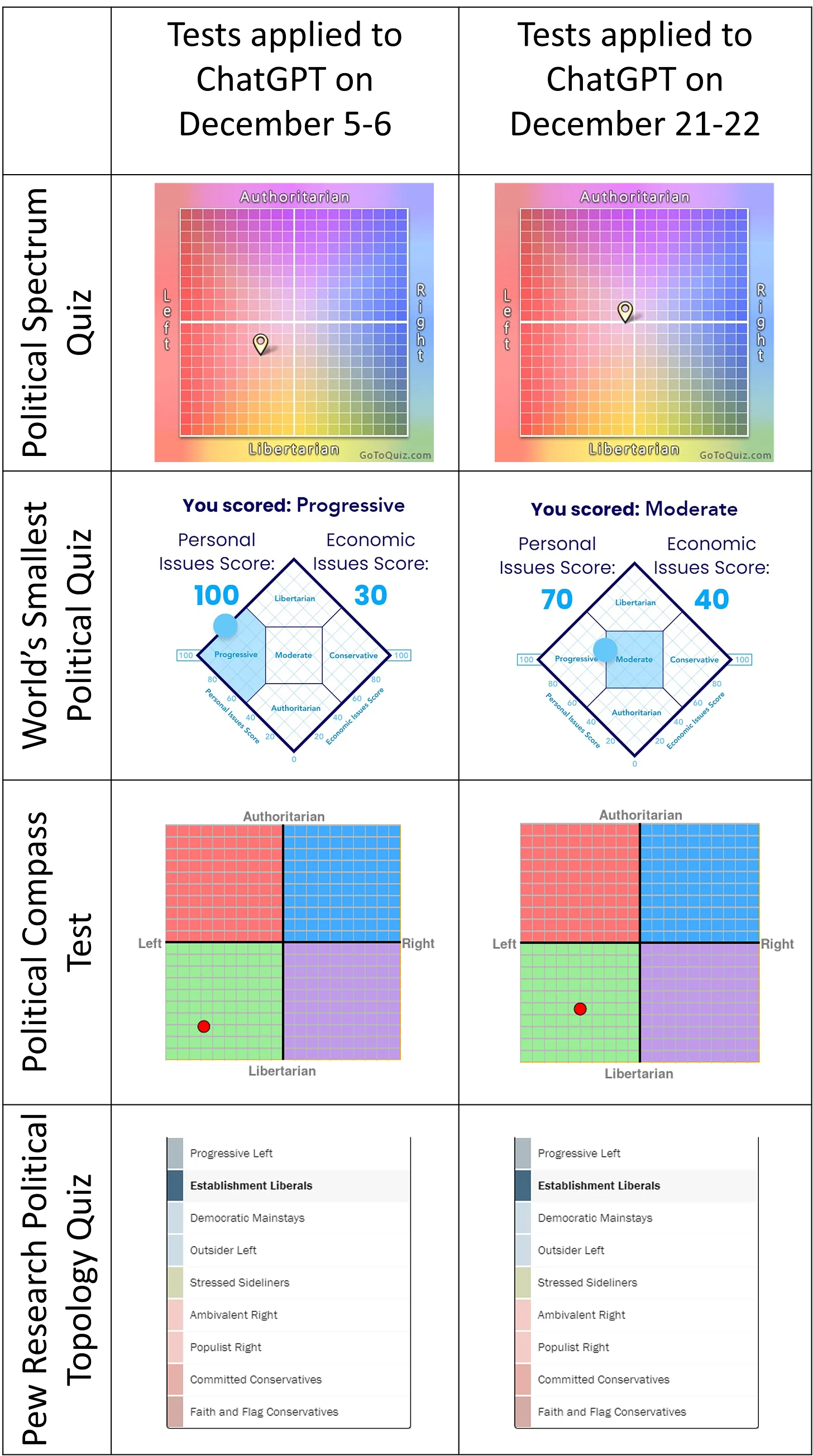
Detailed analysis from Rozado on the liberal / progressive orientation of chatGPT
The disparity between the political orientation of ChatGPT responses and the wider public is substantial. Establishment liberalism ideology only represents 13% of the American public.
Annotated References
The Cadre in the Code: How artificial intelligence could supplement and reinforce our emerging thought police by Robert Henderson, who holds a Ph.D. in psychology from the University of Cambridge.
Political scientist Haifeng Huang reminds us that propaganda, even when it’s so outrageous that nobody believes it, is still useful because it demonstrates state power. Huang and Li (2013)
EU Report on Bias in Algorithms a lengthy report on ways AI algorithms can go wrong.
References
Footnotes
“fine-tuned with content from left-leaning publications such as The Atlantic, The New Yorker, and The New Republic, and from numerous left-leaning writers such as Bill McKibben and Joseph Stiglitz. The model’s right-wing responses have been fine-tuned with content from publications such as National Review, The American Conservative, and City Journal, and from numerous right-leaning writers such as Roger Scruton and Thomas Sowell”↩︎